

One of the main measures of an artificial intelligence (AI) compute cluster performance is JCT (job completion time). The shorter the JCT, the better utilized the cluster and the faster it can move to the next training or inference job, however, it turns out that the choice of the networking fabric, connecting the GPUs of such a cluster in a back-end network, can significantly impact such a performance.
Independent lab testing of different architectures of such networking fabric, conducted by Scala Computing, provided hard evidence of this effect, comparing JCT performance when using DriveNets Network Cloud DDC (Distributed Disaggregated Chassis) architecture and the other Ethernet-based architecture alternative, Ethernet Clos.
Testing methodology
Scala Computing tested the following architectures:
-
Network Cloud-AI DDC (NC-AI DDC): a 2000 x 400 Gbps port scheduled fabric architecture. This architecture utilized Broadcom DNX chipsets (specifically, Jericho3-AI for the leaf nodes and Ramon3 for the spine) implemented in new whiteboxes from Accton, supporting 18 x 800 Gbps client interfaces per box.
-
Ethernet Clos: a 2000 x 400 Gbps port Ethernet fabric architecture (Broadcom Tomahawk 5 for leaf and spine). The Tomahawk 5 (TH5) chipset was selected as an example of a high-end layer-2 switch in ASIC. Similar ASICs are available from other platforms.

Scala Computing conducted the tests on a 2000 GPU setup, with each GPU connected to a 400 Gbps Ethernet port. Workloads used for the tests were machine-learning training workloads. Specifically, the process tested was collective reduction over RoCE (Remote Direct Memory Access [RDMA] over Converged Ethernet), with an NCCL (NVIDIA Collective Communications Library) dual B-tree.
Four workloads were run in parallel, split evenly between the 2000 GPUs, to simulate a multi-tenancy environment such as an AI cloud infrastructure. Such an environment needs to support multiple customers with their unique workloads on a single platform and maintain multi-tenancy guidelines such as data sovereignty, security, etc.
The measured results were compared to an ideal theoretical result, which was set as a reference plane with the value “1”. This ideal result is the forecasted result for a full-mesh, non-blocking architecture, in which all GPUs are connected directly to all GPUs, without any latency or degradation on the line. (This is a theoretical scenario for the purpose of benchmarking.)
Scala Computing ran the test in three phases:
-
Steady-state stage, in which no impairments were introduced to the setup, measuring JCT performance of the infrastructure using an all-to-all collective between the 2000 GPUs.
-
Impairment stage, in which a 50% throughput reduction was impaired onto the network interface cards (NICs) related to one of the four workloads. The aim of this test was to simulate a “noisy neighbor” environment and measure the impact on performance of each workload.
-
Fabric speed stage, in which performance was compared for similar setups, where fabric line speeds were changed from 800 Gbps to 400 Gbps. The goal of this test was to measure the JCT performance impact due to hashing across ECMP groups in an Ethernet CLOS solution compared to DDC cell-based distribution.
Steady-state stage results
The following results were measured when testing workload JCT in the two architectures: DDC/DNX and Clos/TH5

The DNX-based DDC architecture showed a near-ideal JCT figure, thanks to its lossless, predictable and cell-based fabric. The TH5-based Ethernet Clos architecture, however, showed figures that are about 10% higher than DDC and around 14% higher than the ideal performance figure.
This is a significant result; a 10% improvement in JCT, over a long period of time (i.e., steady state) means one can use roughly 10% less GPUs to achieve the same results. This is a significant cost reduction for anyone wishing to build a large-scale AI cluster, as the network, which costs around 10% of the entire setup, practically pays for itself.
Impairment stage results
At this stage, the noisy neighbor effect on each architecture is measured. This is important for a multi-tenancy environment, such as multiple enterprise workloads sharing the same GPU cluster and interconnect fabric for training or inference.
Impairing a 50% reduction on network interface cards (NICs) of workload 1 (of the four workloads in total), the test shows that the Ethernet Clos architecture has a linear effect on all workloads sharing the same infrastructure. This is due to the way the PFC (priority-based flow control) mechanism works. When a NIC experiences congestion, it signals “STOP” to the connected leaf switch. This switch subsequently back propagates this measure throughout the network, which results in a throughput decrease affecting all of the connected devices in the network.
Performance degradation in the DDC architecture, however, is limited to the impaired connection only, thanks to the end-to-end virtual output queue (VOQ) mechanism.

A GPU noisy neighbor scenario occurs when the performance of one or more GPUs is negatively affected by the activity of other GPUs on the same node. This can happen for a variety of reasons, such as resource contention on the network or performance degradation on the NIC.
The results show that Network Cloud-AI is optimized for GPU noisy neighbor scenarios, ensuring no performance impact on other AI jobs running in parallel.
Fabric speed stage results
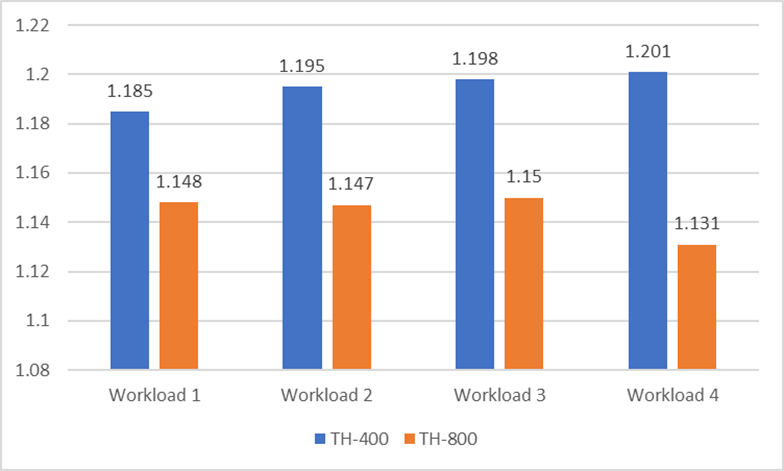
Lastly, fabric speeds were varied between 400 Gbps and 800 Gbps.
Since the Network Cloud-AI DDC architecture is based on a cell-based fabric, the fabric line speed does not affect the fabric performance and the customer can select a 400 or 800 Gbps fabric according to its preference.
For an Ethernet Clos architecture, however, a 400 Gbps fabric will need twice the number of ports, hence twice the ECMP (Equal-cost multi-path routing) group size, which degrades performance, as shown in the graphic below.
What does this all mean?
Scala Computing’s independent testing reaffirms data from various field deployments, according to which the Network Cloud-AI solution yields the highest JCT performance, enabling faster training and deployment of large-scale AI models. This is true in both steady-state and impaired environments, insuring highest performance in a multi-tenancy environment. Fabric speed flexibility also allows a performance-proofed 400 to 800 Gbps migration process.